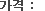|
|
|
|
|
 |
저는 데이터 엔지니어링을 "정확한 의사결정을 가능하게 만드는 생산라인"이라고 봅니다.
신뢰성, 재현성, 비용 통제입니다.
저는 특히 "데이터 계약"을 중요하게 봅니다.
원인 분석입니다.
캐시는 만능이 아니라 비용입니다.
신뢰 가능한 범위만 제한적으로 제공하는 방식입니다.
데이터 신뢰를 깨면 팀 전체가 손해를 봅니다.
저는 데이터 엔지니어링을 신뢰 가능한 의사결정을 가능하게 만드는 생산라인이라고 정의하는 지원자입니다.
|
|
|
 |
좋은데이터파이프라인의 조건 3가지를 말해주세요
SlowlyChangingD im ens ion을 어떻게 이해하고 적용해보셨는지 말해주세요
데이터파이프라인 장애가 났을 때, 우선순위와 대응 절차를 말해주세요
Spark를 쓰는 이유와, 성능 튜닝을 어떤 순서로 하는지 말해주세요
인턴 기간 동안 본인이 만들고 싶은 구체적 산출물 2가지를 말해주세요
압박 질문 : 인턴이 만든 파이프라인이 장애를 내면 누가 책임지나요
압박 질문 : 데이터가 틀렸는데도 분석팀은 오늘 리포트를 내야 합니다.
압박 질문 : 클라우드 비용이 폭증했습니다.
저는 데이터 엔지니어링을 "정확한 의사결정을 가능하게 만드는 생산라인"이라고 봅니다.
원천을 최대한 보존하고, 변환은 모델 계층에서 관리하면 변경에 강합니다.
켄뷰 같은 소비재 기업은 채널과 지역이 넓 고민감정보 가능성도 있어서, 저는 "원천적재는 보존하되 접근 통제와 마스킹을 강하게, 변환은 표준모델계층에서"라는 접근이 맞다고 봅니다.
저는 분석 목적의 서빙레이어에는 스타스키마가 실무적으로 강하다고 봅니다.
제가 했던 프로젝트에서는 상품 속성테이블에서 브랜드 라인이 변경되면서 과거 캠페인성과가 재분류되는 문제가 있었는데, SCDType2로 이력을 남기고 "캠페인 당시기 준"과 "현재 기준"을 모두 조회 가능하게 만들어 논쟁을 끝냈습니다.
입력 검증입니다.
변환검증입니다.
품질 이슈가 있을 때는 테이블에 신뢰도 플래그를 두고, 다운스트림이 자동으로 경고를 받게 합니다.
언제 복구되고 어떤 데이터가 신뢰 가능한지, 불확실성은 무엇인지까지 투명하게 공유해야 합니다.
의존성의 명확성, 재실행 가능성, 관측 가능성입니다.
증분적 재의 핵심은 무엇이 바뀌었는지 식별하는 키입니다.가장 단순한 방식은 updated-at 기반입니다.
그리고 증분적재에는 반드시 삭제처리 전략이 필요합니다.
작업별 비용 태깅과 쿼리 감사로 그를 기반으로 "누가 무엇을 얼마나 쓰는지"를 투명하게 만드는 것이 출발점입니다.
데이터 품질 게이트를 포함한 표준 파이프라인 템플릿을 만들고 싶습니다.
또한 제가 만든 파이프라인은 기본적으로 롤백 가능해야 합니다.
책임을 회피하지 않되, 사고가 나지 않게 만드는 방식으로 일하겠습니다.
신뢰 가능한 범위만 제한적으로 제공하는 방식입니다.
테이블 정의, 지표정의, 변경 이력을 남겨 다음 사람이 이어서 운영할 수 있게 만들겠습니다.
그래서 저는 먼저 지표정의서와 데이터 계약을 만들고, 변경은 버전으로 관리하겠습니다.
저는 그 변화 자체를 잘못으로 보지 않고, 변경 비용을 낮추는 설계를 하 겠습니다.
운영이 답입니다.
파티셔닝과 스캔 최소화, 공통 모델 재사용, 관측 기반 비용 통제로 낭비를 줄이겠습니다. |
 |
데이터, 만들다, 이다, 비용, 가능하다, 파이프라인, 어떻다, 변경, 보다, 적재, 방식, 모델, 분석, 쓰다, 바뀌다, 해주다, 말, 품질, 설계, 기반 |
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|







 2025.12.26
2025.12.26 9페이지
9페이지