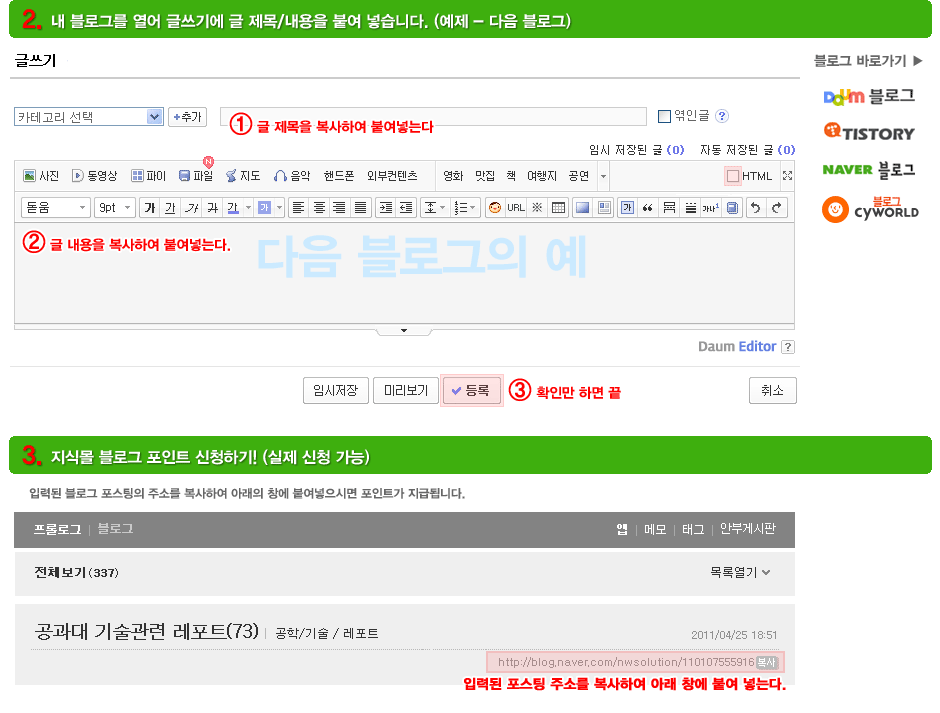
올린글을 확인할 수 있도록 포스팅을
공개
로 설정해 주세요.
포인트는 운영자가 올린글을 검토후 지급됩니다. 검토요청이 누적된 상황에서는 포인트 지급에 상당한 지연이 발생할 수 있습니다.
이 단계에서 첫 산출물은 데이터 소스맵, 데이터 정의서, 그리고 품질 기준 표입니다.
데이터 엔지니어가 가장 먼저 해야 할 일은 "같은 숫자를 보게 만드는 것"입니다.
제조 데이터는 누락과 지연이 일상입니다.
데이터 모델링 역량입니다.
데이터 품질과 관측 가능성 역량입니다.
표준화는 현장마다 다른 정의를 같은데이터 모델로 묶는 것입니다.
현장이 원하는 것은 모든 데이터가 아니라, 의사결정에 필요한 최소 데이터입니다.
저는 스마트팩토리에서 데이터가 전략이 아니라 일상이 되도록 만들겠습니다.
저는 이 '지금'에 쓸 수 있는데이터를 만들고 싶습니다.
그래서 현대오토에버스마트 팩토리 DataE ngineer, 데이터 파이프라인 개발 및 운영 직무에 지원합니다.
현대오토에버를 선택한 이유는 스마트팩토리가 단순 시스템 구축이 아니라, 현장 운영의 표준을 만드는 사업이기 때문입니다.
저는 이 표준을 코드로 만드는 일을 하고 싶습니다.
파이프라인은 한번 만들고 끝내는 것이 아니라, 현장의 변화와 함께 계속 살아있어야 합니다.
장기적으로는 스마트팩토리 데이터가 분석과 AI로 자연스럽게 이어지도록 데이터 제품 관점의 플랫폼을 만들겠습니다.
저는 현대오토에버에서 데이터 파이프라인 운영을 ' 운영업무'로 남기지 않고, 현장 경쟁력으로 바꾸는데이터 엔지니어로 성장하겠습니다.
데이터 모델링과 저장 전략.둘째, 스트리밍과 배치 파이프라인의 안정성 설계.셋째, 데이터 품질과 관측 가능성 운영입니다.
파이프라인 안정성 설계 역량입니다.
데이터 품질과 관측 가능성 역량입니다.
예를 들어 결측률, 중복률, 지연시간, 값의 범위, 분포 변화, 장비별 outlier를 품질지표로 두고, 임계값을 넘으면 자동 알람이 발생하게 했습니다.
파이프라인을 만든 뒤, 지연과 누락을 일부러 발생시키고, 재처리로 복구되는지 테스트했습니다.
신뢰성은 누락과 지연이 발생해도 일관된 결과를 내는 능력입니다.
이를 위해 이벤트 타임 기반 처리, 멱등성업서트, 재처리 자동화를 포함한 아키텍처를 설계하겠습니다.
지표는 데이터 지연시간, 재처리 성공률, 결측률, MTTR입니다.
표준화는 현장마다 다른 정의를 같은데이터 모델로 묶는 것입니다.
지표는 표준 스키마 적용률 , 정의 충돌 건수 감소입니다.
규칙은 결측률, 중복률, 지연, 값 범위, 분포 변화, 참조무 결성 같은 항목을 데이터셋별로 정의하는 것입니다.
수집은 엣지 게이트웨이를 두어 내부망에서 데이터를 집계하고, 필요한데이터만 암호화해 전송하는 구조가 안전합니다.
먼저 어떤 데이터 셋이 비용을 주도하는지 파악하고, 처리량과 비용의 비율을 확인합니다.
마지막으로는 비용 알람과 예산가드레일을 구축해, 특정 기준을 넘으면 자동으로 원인 분석이 시작되도록 만들겠습니다.
[hwp/pdf](스마트팩토리) Data Engineer_데이터 파이프라인 개발 및 운영(2026신입) 자기소개서 자소서 및 면접질문
포스팅 주소 입력
올린글을 확인할 수 있는 포스팅 주소를 입력해 주세요.
네이버,다음,티스토리,스팀잇,페이스북,레딧,기타 등 각각 4개(20,000p) 까지 등록 가능하며 총 80,000p(8,000원)까지 적립이 가능합니다.